Codificação de Texto
Esta página foi escrita para os alunos do
BCC
e não pretende ser uma fonte de consulta para leitores de fora, apesar de que
várias informações podem ser úteis a terceiros.
Atualizado pela última vez em 02/SET/2016.
Entendendo os problemas
Computadores só trabalham com números. Qualquer outro tipo de informação
precisa ser representada por números para ser processada por computadores.
Texto é um desses outros tipos de informação que precisa de uma representação
numérica nos computadores.
Infelizmente, existem dificuldades na padronização dessa representação,
ou seja, texto não é representado sempre da mesma forma nos computadores.
Desta forma, é preciso conhecer um pouco do assunto para se evitar problemas
com a transferência de texto entre sistemas.
Padrões existem, mas não são perfeitos e nem sempre são utilizados. O primeiro
padrão importante para codificação de texto foi o ASCII, publicado pela primeira
vez em 1963. Esse padrão definia a codificação de caracteres usados nos Estados
Unidos como letras do alfabeto inglês, algarismos,
caracteres
de controle para
teletipos e alguns
outros símbolos gráficos.
A versão original do ASCII definia 128 caracteres, que obviamente, são insuficientes
para representar os vários símbolos gráficos das mais variadas culturas como desejamos
fazer hoje em dia.
As primeiras extensões importantes do ASCII definiam 256 caracteres, aproveitando
a quase universalidade dos sistemas baseados em 8 bits. Infelizmente 256 caracteres
ainda eram insuficientes para garantir a padronização da representação de texto num
mundo cada vez mais informatizado. Sugiram diversas extensões padronizadas de ASCII,
em geral mantendo os primeiros 128 caracteres inalterados e definindo os outros 128.
Sugiram padrões como o ISO-8859-1 (muito usado até hoje no Brasil) e seus irmãos
usados em regiões com necessidades diferentes, como por exemplo o ISO-8859-6 usado
pelos árabes. O problema é que os sistemas computacionais só poderiam utilizar um desses
vários padrões já que todos eles têm definições conflitantes para os novos 128 caracteres.
Para piorar a situação, uma grande empresa da área de informática evitou por muitos
anos o uso desses padrões, forçando o uso de suas próprias definições como o
WINDOWS-1252.
Recentemente, um novo sistema de codificação de caracteres foi padronizado numa
tentativa de resolver os problemas de codificação de caracteres.
Com cerca de 100 mil caracteres distintos, o Unicode vem ganhando suporte
num número cada vez maior de sistemas, principalmente na forma do UTF-8, uma implementação
de Unicode em que os caracteres comuns (aqueles sem acento) são representados por oito
bits, enquantos outros (em especial aqueles com acento) são representados por mais bits.
Mojibake
Mojibake é o mais comum dos problemas com codificação de texto. Ele pode acontecer
na visualização de uma página WEB, na leitura de uma mensagem de correio eletrônico,
na execução de um programa, ou em qualquer outro caso em que informação textual
é transferida de um sistema para outro. Consiste na apresentação de um simbolo
gráfico que não corresponde ao desejado. As duas figuras abaixo apresentam
exemplos de mojibake.

Texto codificado com UTF-8 e interpretado como ISO-8859-1

Texto codificado com ISO-8859-1 e interpretado como UTF-8
Mojibake pode acontecer mesmo sem transferir informação de um computador para
outro pois programas diferentes podem estar configurados para usar sistemas
de codificação diferentes. As imagens a seguir mostram um problema comum nos
laboratórios: um ambiente de programação usando um sistema de caracteres
(Dev-Cpp usando WINDOWS-1252) e o terminal do Windows 2000 usando outro (CP437).
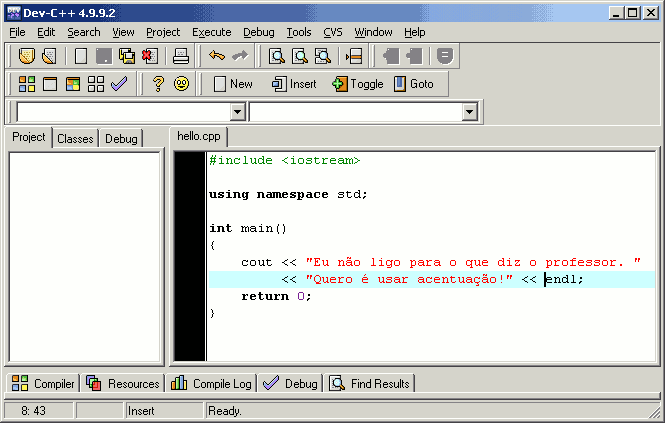
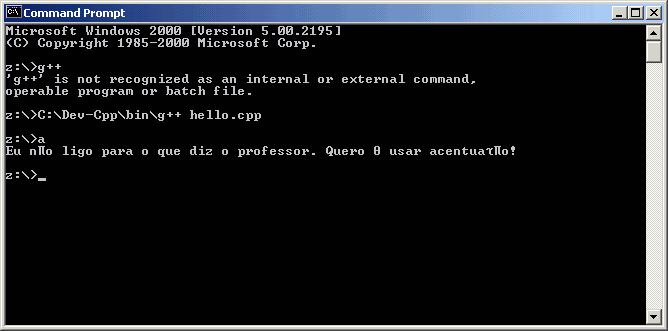
Terminadores de linha
Além dos problemas com os padrões para caracteres, ainda existem os problemas
com a interpretação deles. Os terminadores de linha são um exemplo de discordância.
Dado um arquivo de texto qualquer,
alguns programas (em especial os de Windows) interpretam
que as linhas terminam onde existe uma seqüência de caracteres
CR/LF. Já outros programas
(em especial os de Linux) interpretam que as linhas terminam onde existe o caracter
LF. Existem também outras padronizações possíveis.
O padrão para o sistema operacional MacOS (nas versões anteriores à 10) é o uso do caracter
CR para representar o terminador de linha. Atualmente,
parece que somente as bibliotecas de programação para Windows insistem em usar o
CR/LF enquanto
em todos os outros casos, usa-se somente o LF.
As imagens abaixo apresentam casos em que os terminadores de linhas não são
corretamente identificados em editores de texto.
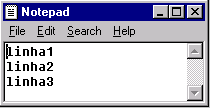
arquivo no formato CR/LF, mostrado no Notepad (Windows)
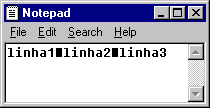
arquivo no formato LF, mostrado no Notepad (Windows)
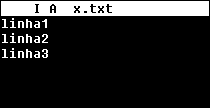
arquivo no formato LF mostrado no Pico (Linux)
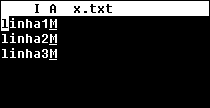
arquivo no formato CR/LF, mostrado no Pico (Linux)
Podemos notar claramente nas imagens a presença de caracteres estranhos quando um programa
utiliza um formato que não entendo. No caso do arquivo no formato LF, mostrado no Windows,
notamos que o programa mostra todo o texto numa mesma linha. O programa do Windows encontra
o LF no arquivo mas não o trata como um caractere comum e não um final de linha, apresentando
um símbolo gráfico em seu lugar. O programa do Linux entende o LF da seqüencia CR/LF como um
final de linha, mas apresenta o CR como um caractere comum, mostrando um símbolo gráfico em seu
lugar.
Alguns programas (em especial os editores para código fonte) são capazes de
reconhecer vários tipos de terminação de linha e não
apenas aquele que é padrão no sistema operacional onde está sendo executado.
É importante conhecer editores que entendam os dois tipos e ser capaz
de usá-los para fazer conversões.
Alguns programas, em função de falhas de programação, ficam perdidos ao encontrar arquivos
que usam mais de um tipo de terminação de linha. A mistura de dois ou mais tipos num mesmo
arquivo é muito mais problemática do que o uso de um único sistema que não seja corretamente
interpretado. Quando for escrever programas em conjunto com outras pessoas, é bom ter
certeza de que o programas usados não vão misturar as várias representações para final de linha.
Medidas preventivas
Ao transferir arquivos entre programas diferentes (principalmente entre programas de sistemas
operacionais diferentes) esteja atento ao sistema de codificação usado. Prefira usar programas
que reconhecem e fazem conversão entre formatos diferentes.
Ao fazer um programa em qualquer linguagem, não use acentos. Nem mesmo nos comentários.
Aprenda a internacionalizar seus programas antes de usar acentos.
Não use acentos em nomes de arquivos.
Nunca tente alterar o sistema de codificação na mão, ou seja, apagando caracteres especiais
e os re-escrevendo depois. Use sempre programas apropriados para isso.
Esta página é mantida por Bruno Schneider